
- Finished editing the manuscript for the 2nd edition of the Perl::PDQ book, which was published in August.
- Finalized the invited chapter A Methodology for Optimizing Multithreaded System Scalability on Multicores (co-authored with Shanti Subramanyam and Stefan Parvu) for the edited volume: Programming Multi-core and Many-core Computing Systems (Wiley-Blackwell).
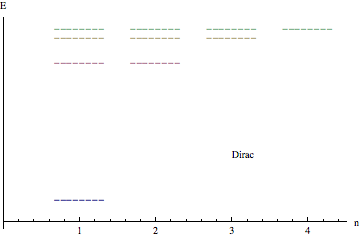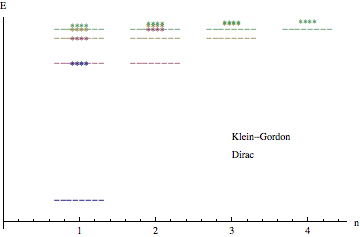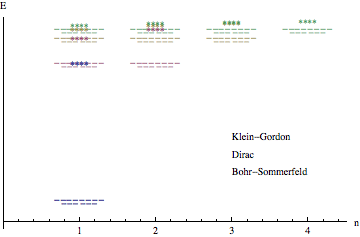
- Sommerfeld-Dirac Paradox: In 1916, Arnold Sommerfeld calculated the relativistic corrections to the Bohr atom and found that the associated perihelion precession produced the known fine structure of the hydrogen spectrum. Remarkably, this is the same result as discovered by Dirac more than a decade later in 1928. The paradox is that the Sommerfeld model does not involve electron (fermionic) spin, whereas spin is intimately involved with the Dirac solution. I originally heard about this paradox from my Masters thesis advisor, Prof. Christie Eliezer, who had been one of Dirac's research students. Recently, it has been suggested that the paradox arises from a fortuitous ambiguity in the way certain of the quantum numbers are defined. If this is so, I believe there ought to be a topological proof. I've got the Lie group algebras down, but it's still a work in progress.
- My ongoing effort to provide a simple pictorial derivation of the Erlang M/M/m queue has been simplified even further.
In case there's any doubt, here's the proof on my whiteboard dated April 13, 2011. ;)

This 2011 "proof" (on my whiteboard) turned out to be not as coherent as I'd hoped. So, I had to give up, again. Finally, in 2020, I can report that I truly have found a consistent way to do what I had in mind in 2011. I know, promises, promises. (sigh!) Anyway, judge for yourself by checking out the new e-print in arXiv.
A different approach was obtained in 2016 but, this is in the form of corrections to the approximate morphing model. See my post entitled, Erlang Redux Resolved! (This time for real) complete with animation of the morphing process.
- Steve Jenkin asked me why the electrical power consumed by a magnetic disk increases as the fifth power of the platter radius. I didn't know it did! So, I decided to see if I could derive the physics from first principles. I was able to do so, but I've yet to find the time to blog about the details. The main point is that the consumed electrical power (Watts) grows as the 5th power of the disk diameter and the 3rd power of the angular speed (RPM). Since these are very fast functions, this relationship is an important result for green datacenter design.
- Together with my colleagues at HP Labs, I've been working on a mathematical model of color naming. If you find yourself having trouble even parsing that sentence, now you know how I felt when I was introduced to this subject. Neuroscientists speculate that the left side of the brain, which deals with language, is also involved in processing colors in the right visual field. More colorful background information can be found on the XKCD blog. This is also a work in progress and I can't say more about our results until they are finally published. I can report, however, that quite unexpectedly, it's turned out to be one of the most exiting pieces of science that I've worked on in a long time.
- In response to having been challenged both publicly (without any supporting data) and privately (with supporting data that I can't reveal publicly) over the need to model so-called superlinear scaling, I've developed a theorem that states such superlinear modifications to the Universal Scalability Law are unnecessary. More on this later.
- I believe I can construct a theorem, which says something like this: The system performance of any computer system, no matter how big or distributed, can always be modeled with just a surprisingly few queueing nodes. How can this be? If you look carefully in my PPDQ book, you'll notice that most (if not all) of the models are relatively simple. Although I've observed this effect many times, over many years, I never put much stock in it. This year, that all changed. I now believe I know why it always works out that way, in general. There will, of course, be some exceptions because you can always add more detail. This theorem also means that it will finally be possible to automatically build your PDQ model directly from collected performance data.
- Designed and road-tested the new GDAT training course.
- Fixed "string" variables (there are no strings in C) in the PDQ library that were causing the R Console to crash. Still have to export the fix to SourceForge.
- Constructed multiple optimization functions for an M/M/m queue to demonstrate that there is no unique way to define optimal load points (ρ*) or "knees" (a misnomer) for response time curves.

For example, for any configuration of m-servers in the above table, which of the functions Y1, Y2 or Y3 represents the correct optimal load (ρ* values in each row)?
- Wrote this blog post. OK, that doesn't count but an odd-numbered list might be unlucky in an even year. :P
{kind=link}
{kind=link}
{kind=link}
9 comments:
#8 would be most handy indeed! But I have to say that I've learned more from building the PDQ models by hand than I ever would have if it had been an automagical system.
PyDQ has been an important part of my 2011 and will be so in 2012 as well.
In the brevity of the statement (and not wanting to give too much away *grin*), I didn't intend to convey that there would be nothing left for the diligent modeler, such as yourself, to do.
Rather, let's say the "automagic" bit would get you to the first-order model, which you could then tweak to your heart's content. The biggest barrier-to-entry for most people is knowing where to start at all. And usually, the start (too) big.
WIthout naming names, I just went through a group exercise in a recent training class where the initial PDQ model was declared (by those in the know, not me) to contain everything including the proverbial kitchen utensils. This went on for some time and nothing seemed to jive. Then, I took over and showed how, from a performance perspective, the initial model inevitably got winnowed down to about 3 queues whereupon it was immediately observed to align with the available performance data. My objective, on the other hand, was not necessarily to simply (per se) but to reach a point where the various queueing metrics became consistent.
Instead of building down, we could build up.
I'm honored to have become a link in your list. I can provide supporting data if you like, but I doubt you need it. I look forward to learning more about how the USL can explain this effect, because I haven't thought of any way to model it without increasing the complexity of the USL by adding terms, and its simplicity is what makes it so powerful in the "real world" for me.
Neil, I would agree very strongly with your statements about making the model simple rather than including kitchen sink. Part of my problem has been to how to include the software locking processes that appear to be involved in the DB system and how to know when to add that level of detail. That is often needed to explain why the real world does not scale like the model. There are other artificial limiting factors that are not known at first.
In reading over your blog, it would appear you have been all over the map. Most of all, it sounds like you are still having fun with your work.
Dear Unknown: Nice question and curiously enough it dovetails with item 8 in my list, although I'm not about to go into that here.
Nevertheless, w/o going into a lot of detail, your question can be approached from a queue-theoretic point of view in the following way.
Think of two extremes in time scales. (1) If DB locking is very "short," you don't care (unless it gets longer in the future) and you wouldn't be asking your question. (2) If it's very "long," more than likely something is seriously out of whack or possibly even pathologically broken. In that case there's no point considering performance until the problem is renormalized. A good DBA is worth their weight in gold to help solve problems like that.
For more intermediate cases, the locking can be accommodated as part of the service time. Moreover, you could make the service time load-dependent so as to observe where it becomes a scalability issue that needs to be addressed. See Chap. 12 of my Perl::PDQ book for more on that.
Keep in mind that queueing models see system performance in a time-averaged way, rather the instantaneous view you get when you're staring at perf stats collected by whatever O/S or DBMS tools. Think of that time-averaged view as a kind of "flow" and if you're not flowing, you need to explain why not.
Baron: It all starts and ends with data, but treating data as divine is a sin.
Don't get me wrong, however. I'm not saying that the so-called "superlinear" effect is not observed or that you or other people are making it up. People see all sorts of things in data. People also see UFOs and often have the video to "prove" it.
On the other hand, immediately jumping to the conclusion that aberrant data trumps otherwise successful models is like believing UFOs not only exist but are flown by little green men.
Presenting the data (especially in public commentary) is vital to make your case, either way. Otherwise, it's like saying you've seen a UFO without even having a video on YouTube; a mere hit-and-run tactic.
There is a nice role model for this situation in particle physics at the moment. You've probably seen the incessantly repeated reports that Einstein is toast b/c superluminal neutrinos have apparently been observed (twice) in the CERN/OPERA detector.
Although the press and bloggers were all over this (and CERN probably didn't mind the publicity) the physics team involved, to their credit, presented their data both aurally and in a peer-reviewed journal. And their data can't be dismissed easily b/c it's accurate to 6-sigma (i.e., 1 in a billion chance that it's a fluke). Basically, they are saying: "Help!" this is what our data reveals when we interpret it, but we can't explain why it contradicts more broadly tested and known physics. They did not push the idea that SRT is dead; that was bloggers.
The jury is still out on OPERA (I believe) but I'm putting my money on Albert. I'm betting there's a bug in the measurement apparatus or the way the data analysis is being executed. Because of the immense complexity in their measurements, however, it willl probably take a long time to sort them out.
Thankfully, superlinearity is a little bit simpler than superluminality. :)
Neil,
I'm not trying to avoid accountability, I'm just really busy. However, it seems pretty clear to me that the USL isn't adequate to model nonlinear cache-dependent behavior. Here is a simple thought experiment. You have a clustered system with a readonly workload, where each node contains 10GB of RAM. The total dataset is 50GB, and is uniformly accessed (for simplicity, but in another paragraph or two I could extend this to a realistically accessed dataset; it just gets confusing in an unhelpful way that doesn't change anything material). The data is stored on some kind of hard drives; doesn't really matter what. The only thing that matters is that the drives are much slower than RAM.
Now, after the system warms up, a one-node cluster will have a 20% cache hit rate. 4/5ths of the accesses will go to disk.
Let's add another node and let the cluster warm up. A smartly designed clustering system explicitly creates locality of cache reference: operations on half the dataset goes to one node, and the others go to the other node. The data may even be partitioned instead of duplicated; it doesn't matter. We now have each node effectively dealing with half the data, so the cache hit rate has improved nonlinearly, and you can easily calculate what happens to the system throughput as a result.
Add a few more nodes to the system, and the workload becomes entirely in-memory, and I/O is nonexistent. Suddenly each node is performing a few orders of magnitude faster than a single node did. We multiplied the node count by 5, and got 1000-fold improvements.
I see this kind of thing all the time in the real world.
There is no violation of the laws of physics, no UFO, no green man. The USL isn't the complete story here.
To define scalability on such a system, we have to hold a lot of things constant. The USL says we hold the workload per node constant, add nodes, and see what happens. But "workload" is much more than just number of client programs. In addition to that, we need to hold the data per node constant, so we need to scale the data size. But we also need to look at query complexity, because the interrelationships between bits of data commonly grow nonlinearly too; so in the end it becomes very complex to understand what constitutes an equal workload per node as the cluster grows.
If the USL is capable of modeling this, I would like to understand how, but I frankly don't think it is. The USL is a simpler model, just as Newton's laws are a pretty close approximation as long as you don't move very fast.
I don't think you need real datasets and benchmark results to agree that this is possible and doesn't represent bad data, bad measurements, etc. I'm frankly quite surprised you haven't run into this type of thing yourself.
I'm not arguing that a single node can magically do more work than it can do, and really scale superlinearly, or that we're getting something for nothing; I'm saying that our definition of linear is not adequate.
Baron, It seems to me you want it both ways: "I see this kind of thing all the time in the real world," but you don't provide data because "I'm just really busy."
With data, we don't need thought experiments. Your example, btw, is pretty much the canonical example of how superlinear effects arise.
Sounds like we agree. No little green men in sight!
Post a Comment